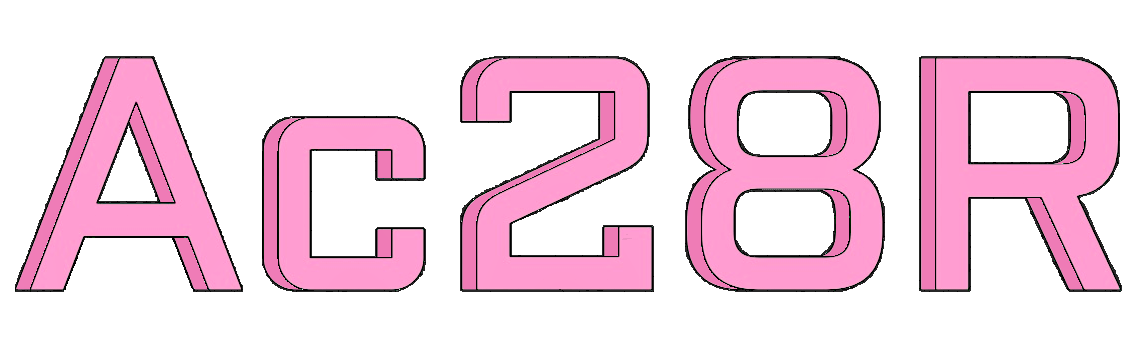
●
Ac28R can create software based on the structures of Inverts from any of the libraries.
●
So far, we have created libraries to handle all of the types of components that would be seen in most typical software programs. And for good measure, we included the kinds of structures that would be seen in an analytical spreadsheet.
●
These libraries have been supplemented with a growing number of specialised libraries that cover probability and random models, statistics, risk and insurance, as well as certain specialised models covering queues and epidemiology.
●
A number of other libraries are currently under construction and we hope to announce them shortly.
●
Within each library, we believe we have a comprehensive set of Inverts.
●
So, if you see a library covering a topic of interest, it is highly likely that it would cover everything that you need.